Course Summary
Notes and resources
Big Picture
What we want to do
We want to move from raw data to research outputs.

What we do
For each manuscript we can individually ETL (aka data wrangling) then store it where ever we want.
This results in a lot of repeated work across projects and a lot of repeated work.

*ETL
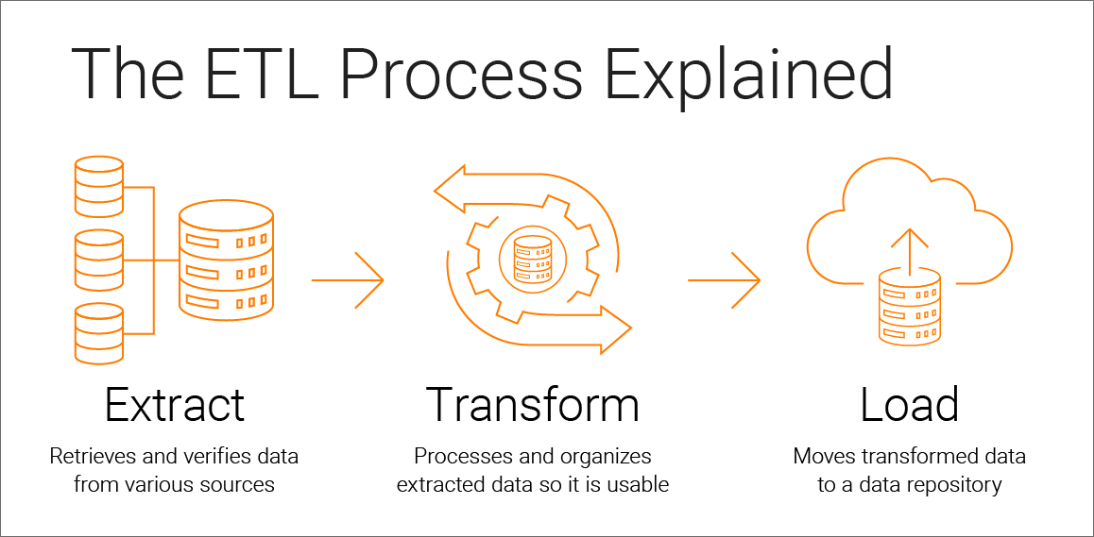
Many organization have faced this issue and the industry solution is datawahousing.
How Data warehousing can help
We can organize our work so that data wrangling (including complex methods such as model-based imputations) are done by individual groups. But once data is structured we can deposit into data warehouse as primary data aka Seeds.
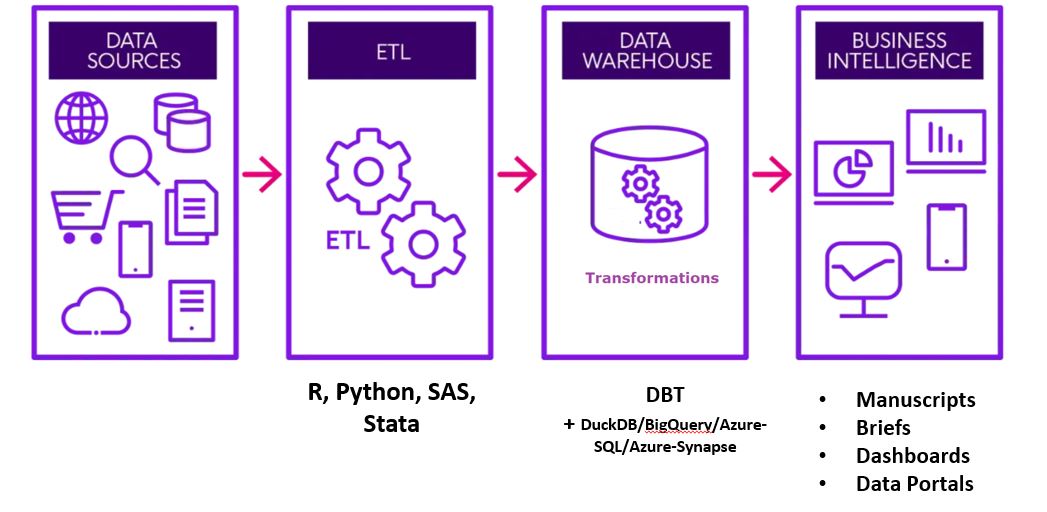
We can then centralize the transformations of primary/seed data into what ever downstream outputs we want. All under the best practices frame work of DBT which provides a very mature workflow for organizing queries, generating documentation, version control and collaborative environment management.
Course Content
- Session 1 (5/10/23): Get Started + Setup
- setup software required for DBT
- Session 2 (5/24/23): Loading data into DBT
- Start with source data (.csv or .parquet or .json)
- Load source data into DBT
- Generate documentation
- Session 3 (5/31/23): Intro to Modeling
- Intro to structure
- Base models
- Interactive modeling
- Session 4 (6/7/23): Modeling Fundamentals
- Session 5 (6/14/23): Standups + Intermediate Features
- Stand-ups
- Working on the cloud
- Cloud storage
- Cloud database example
- Summary
Moving Forward
Somethings to keep in mind before we start
This course is not a comprehensive guide to data warehousing with DBT but rather meant to get you started in terms of software and introduce basic concepts. Please see the following for more resources to help you learn.
-
- dbt fundamentals
- dbt Jinja, Macros, Packages
- Note, these courses DBT cloud but you can use the set up we introduce to practice
-