The goal of this workshop will be to give you a basic introduction to SQL for the purposes of querying (or extracting data) from a database for use in your projects.
Outline
Overview of Relational Databases and SQL
How to connect to a SQL Database
Writing SQL Queries
Exporting data
Practice and exercises
Relational Databases
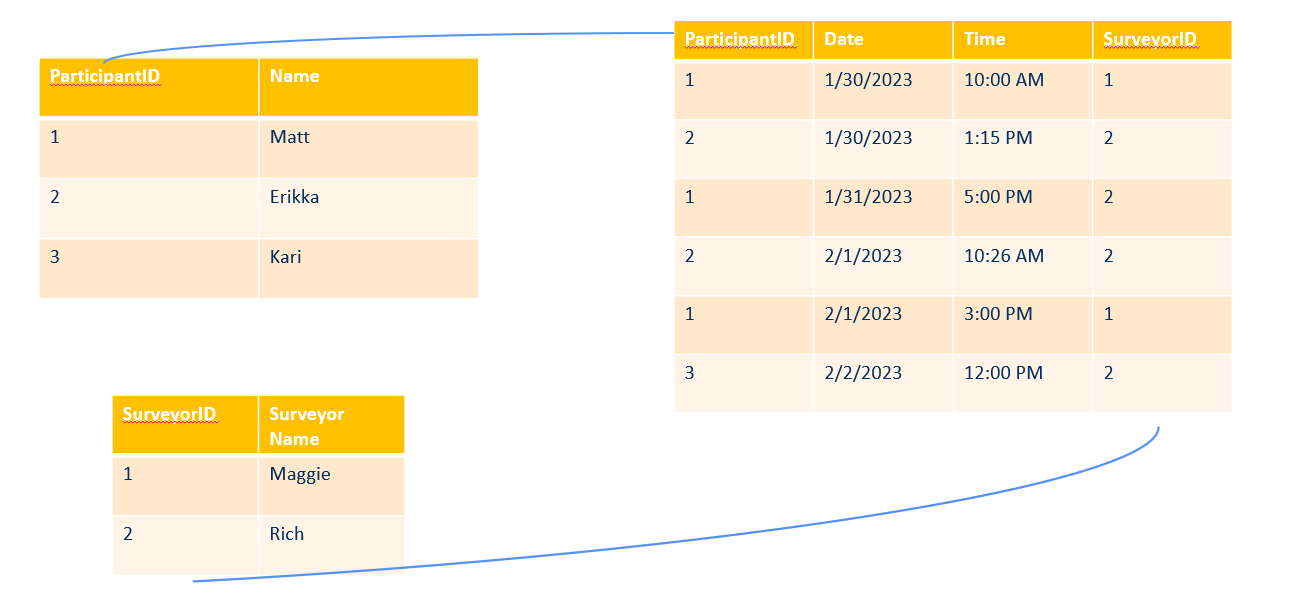
At it’s core a relational database is just a series of interconnected tables.
While there is a lot of other functionality of databases, to grasp the basics of querying data you can think of it like a series of:
excel spreadsheets
R/Python dataframes
SAS datasets
All of the tables in a SQL database will connect to at least one other table in the database. It will be connected by a set of keys. These keys work similarly to ID columns that you might use when merging two datasets in your favorite analytic software.
image.png
Advantages of relational databases
Data can be centrally stored
Data types and constraints are enforced
Data is consistent and available to everyone with access
If the data is relatively large, you can do a lot of the transformations on the database server
There are plenty of other advantages not discussed here, but they will mostly not come up in this workshop.
What is SQL
SQL (Structured Query Language) is a set of standards for interacting with relational databases.
There are A LOT of different versions of SQL, each is slightly different.
image.png
If you know how to interact with one of these, you can pretty easily figure out the others.
SQL Server and Azure SQL
This workshop will use SQL Server/Azure SQL, which is Microsoft’s version of SQL.
Drexel and the UHC already uses Azure
Drexel provides a personal liscence to Drexel employees and students.
We can all use our Drexel credentials to access a remote database set up for this workshop
There are some differences between SQL Server and Azure SQL but they won’t come up during our exercises. For our purposes, they are essentially interchangeable.
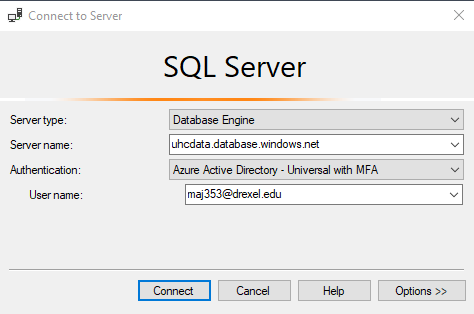
Put the name of the server in the “server name” box (uhcdata.database.windows.net)
Switch the “Authentication” to “Azure Active Directory - Universal wtih MFA”
Put in your Drexel email in the “User name” field
Press connect. You will be prompted for your Drexel password. And you will need to have your phone handy for the 2-factor authentication.
Connecting to the Example Database
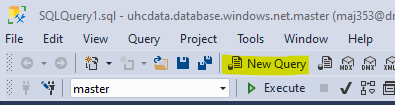
In the top left corner, select “New Query”
image.png
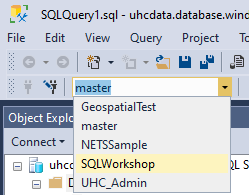
Then click the dropdown and select “SQLWorkshop”
image-2.png
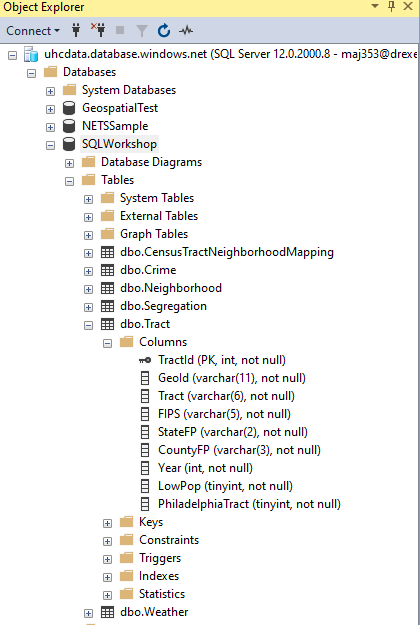
Using the Object Explorer
The object explorer is the left hand pane, it shows the databases on the server. You can also expand the databases to see the tables and the tables to see the columns in each table.
image.png
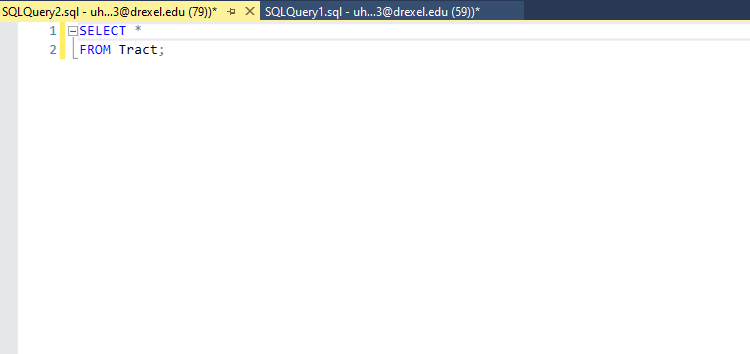
Query Writing UI
The top of the main section of the window is where you will write your queries.
image.png
When you want to run a query, highlight the portion of the text you want to run and press the execute button up top
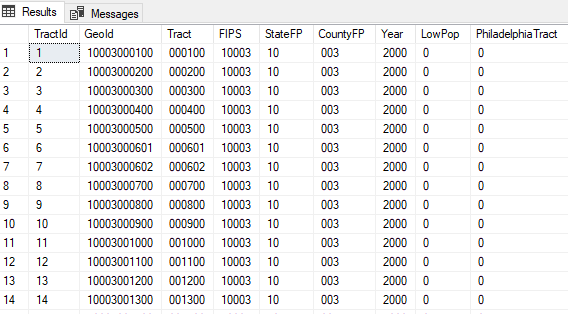
Query Results
The bottom half of the main window is where the query results will display.
image.png
you can click the “Messages” tab to see messages about status or other console type messages.
How to Write a SQL Query
SQL queries or statements is how you look at and extract data from a SQL server.
Each query is separated into “clauses”
Learning the basic clauses and some extra keywords is enough to do the vast majority data manipulation in SQL
The Clauses
FROM: picks which table in the datatable that you are starting with
SELECT: picks which columns of the from table and joined tables appear in the result
WHERE: filters which rows are included in the result
JOIN: merges other tables with the from table
Extra clauses
ORDER BY: sort by a column or series of columns (combine with the DESC keyword to control the order)
GROUP BY: used to aggregate rows by a given column or series of columns (used with some keywords to produce things like averages and counts)
SELECT*FROM [table]
SELECT [column1], [column2]FROM [table]
SELECT*FROM Tract
TractId
GeoId
Tract
FIPS
StateFP
CountyFP
Year
LowPop
PhiladelphiaTract
0
21329
10003000100
000100
10003
10
003
2000
0
0
1
21330
10003000200
000200
10003
10
003
2000
0
0
2
21331
10003000300
000300
10003
10
003
2000
0
0
3
21332
10003000400
000400
10003
10
003
2000
0
0
4
21333
10003000500
000500
10003
10
003
2000
0
0
...
...
...
...
...
...
...
...
...
...
5327
26656
24015030904
030904
24015
24
015
2020
0
0
5328
26657
24015030700
030700
24015
24
015
2020
0
0
5329
26658
24015031202
031202
24015
24
015
2020
0
0
5330
26659
24015031400
031400
24015
24
015
2020
0
0
5331
26660
24015030503
030503
24015
24
015
2020
0
0
5332 rows × 9 columns
SELECT GeoId, FIPS, PhiladelphiaTractFROM Tract
GeoId
FIPS
PhiladelphiaTract
0
10003000100
10003
0
1
10003000200
10003
0
2
10003000300
10003
0
3
10003000400
10003
0
4
10003000500
10003
0
...
...
...
...
5327
24015030904
24015
0
5328
24015030700
24015
0
5329
24015031202
24015
0
5330
24015031400
24015
0
5331
24015030503
24015
0
5332 rows × 3 columns
Keywords in the SELECT Statement
There are plenty of keywords or functions you can use in the select statement to modify the output.
For example, the top keyword will let you pick the first N rows of a query
SELECT TOP 5 GeoId, FIPS, PhiladelphiaTractFROM Tract
SELECT GeoId, FIPS, PhiladelphiaTractFROM TractWHERE (PhiladelphiaTract=1OR StateFP='34') AND LowPop=0
The first query returns 2627 rows but the second returns 2573. Why?
Hint
The number of New Jersey tracts stays the same in the results, but the number of Pennsylvania census tracts goes down in the second query.
StateFP
PhiladelphiaTract
Count
0
34
0
1454
1
42
1
1173
StateFP
PhiladelphiaTract
Count
0
34
0
1454
1
42
1
1119
Answer
This conditional pulls all Philadelphia census tracts and only New Jersey census tracts that are not low population.
WHERE PhiladelphiaTract=1OR StateFP='34'AND LowPop=0
This conditional pulls all low population census tracts in Philadelphia and New Jersey. The second query removes the low population Philadelphia tracts that were included in the first query.
WHERE (PhiladelphiaTract=1OR StateFP='34') AND LowPop=0
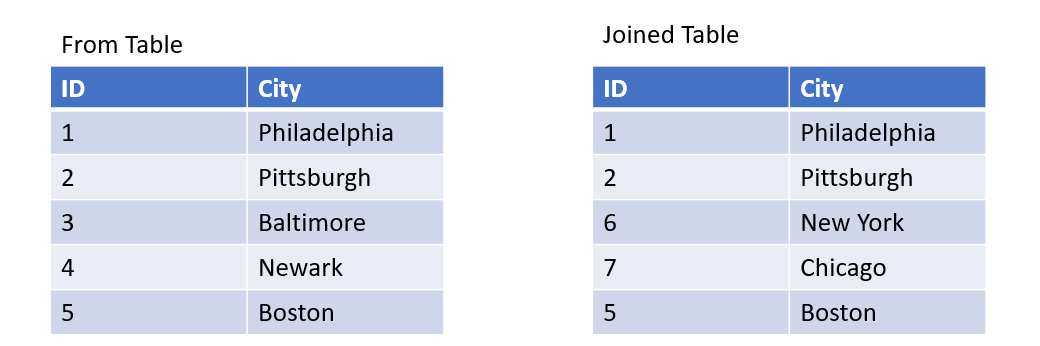
Joins
If you need to combine multiple tables, joins are how you merge tables.
There are multiple types of joins:
LEFT: Keeps all of the data in the from table and fills the joined with NULL if there is no match on the joined table
RIGHT: Keeps all of the data in the joined table and fills the from table will NULL if there is no match
INNER: Keeps only records that are in both tables
FULL: Keeps all records in both tables and fills both the from and joined table with NULL when there isn’t a match
image-3.png
Left Join
ID
From City
Joined City
1
Philadelphia
Philadelphia
2
Pittsburgh
Pittsburgh
3
Baltimore
NULL
4
Newark
NULL
5
Boston
Boston
Right Join
ID
From City
Joined City
1
Philadelphia
Philadelphia
2
Pittsburgh
Pittsburgh
3
NULL
New York
4
NULL
Chicago
5
Boston
Boston
Inner Join
ID
From City
Joined City
1
Philadelphia
Philadelphia
2
Pittsburgh
Pittsburgh
5
Boston
Boston
Full Join
ID
From City
Joined City
1
Philadelphia
Philadelphia
2
Pittsburgh
Pittsburgh
3
Baltimore
NULL
4
Newark
NULL
5
Boston
Boston
6
NULL
New York
7
NULL
Chicago
SELECT Tract.TractId, Tract.GeoId, Weather.MinTemp, Weather.MaxTempFROM TractINNERJOIN Weather ON Weather.TractId=Tract.TractId
TractId
GeoId
MinTemp
MaxTemp
0
24709
10001040100
-3.866622
5.283027
1
24709
10001040100
-3.306153
7.448359
2
24709
10001040100
-0.716506
9.111247
3
24709
10001040100
6.131508
19.015528
4
24709
10001040100
8.402382
20.930977
...
...
...
...
...
311755
24553
42101989100
20.298605
29.906923
311756
24553
42101989100
16.307043
27.830681
311757
24553
42101989100
10.947883
20.478088
311758
24553
42101989100
0.785063
11.659143
311759
24553
42101989100
-0.659598
7.653925
311760 rows × 4 columns
SELECT t.TractId, t.GeoId, w.MinTemp, w.MaxTempFROM Tract tLEFTJOIN Weather w ON w.TractId=t.TractId
TractId
GeoId
MinTemp
MaxTemp
0
24709
10001040100
-3.866622
5.283027
1
24709
10001040100
-3.306153
7.448359
2
24709
10001040100
-0.716506
9.111247
3
24709
10001040100
6.131508
19.015528
4
24709
10001040100
8.402382
20.930977
...
...
...
...
...
315355
22722
42101010700
NaN
NaN
315356
24886
10003002200
NaN
NaN
315357
25427
42101001400
NaN
NaN
315358
25968
42045404800
NaN
NaN
315359
26509
34007605602
NaN
NaN
315360 rows × 4 columns
Chaining Joins
You can join tables on other tables that have been joined in the query to chain tables together.
SELECT t.TractId, t.GeoId, n.NeighborhoodFROM Tract tINNERJOIN CensusTractNeighborhoodMapping ctn ON ctn.TractId=t.TractIdINNERJOIN Neighborhood n ON n.NeighborhoodId=ctn.NeighborhoodId
TractId
GeoId
Neighborhood
0
21474
34005700104
Richmond - Bridesburg
1
21475
34005700200
Wissinoming - Tacony
2
21492
34005700603
Torresdale S. - Pennypack Park
3
21497
34005700800
Torresdale S. - Pennypack Park
4
21595
34007600500
Center City E
...
...
...
...
2746
26338
34007610800
Richmond - Bridesburg
2747
26378
34005700800
Torresdale S. - Pennypack Park
2748
26528
34007600700
Center City E
2749
26528
34007600700
Lower Kensington
2750
26528
34007600700
Northern Liberties - West Kensington
2751 rows × 3 columns
Order By
Sort the result of a query by a column or columns
SELECT t.TractId, t.GeoId, n.NeighborhoodFROM Tract tINNERJOIN CensusTractNeighborhoodMapping ctn ON ctn.TractId=t.TractIdINNERJOIN Neighborhood n ON n.NeighborhoodId=ctn.NeighborhoodIdWHERE t.Year=2020ORDERBY n.Neighborhood
TractId
GeoId
Neighborhood
0
24997
42101034502
Bustleton
1
25034
42101034501
Bustleton
2
25176
42101980300
Bustleton
3
25177
42101035500
Bustleton
4
25179
42101035900
Bustleton
...
...
...
...
996
26022
42101031501
Wissinoming - Tacony
997
26154
34005700303
Wissinoming - Tacony
998
26156
34005700104
Wissinoming - Tacony
999
26246
34005700103
Wissinoming - Tacony
1000
26324
34005700200
Wissinoming - Tacony
1001 rows × 3 columns
Order By Multiple Columns
SELECT t.TractId, t.GeoId, n.NeighborhoodFROM Tract tINNERJOIN CensusTractNeighborhoodMapping ctn ON ctn.TractId=t.TractIdINNERJOIN Neighborhood n ON n.NeighborhoodId=ctn.NeighborhoodIdWHERE t.Year=2020ORDERBY n.Neighborhood, t.GeoId
TractId
GeoId
Neighborhood
0
25699
42091200105
Bustleton
1
26103
42091201501
Bustleton
2
25975
42101034200
Bustleton
3
25976
42101034400
Bustleton
4
25034
42101034501
Bustleton
...
...
...
...
996
25111
42101033000
Wissinoming - Tacony
997
26020
42101033101
Wissinoming - Tacony
998
25259
42101038000
Wissinoming - Tacony
999
25597
42101038100
Wissinoming - Tacony
1000
25109
42101989100
Wissinoming - Tacony
1001 rows × 3 columns
Change the Sort Direction
SELECT t.TractId, t.GeoId, n.NeighborhoodFROM Tract tINNERJOIN CensusTractNeighborhoodMapping ctn ON ctn.TractId=t.TractIdINNERJOIN Neighborhood n ON n.NeighborhoodId=ctn.NeighborhoodIdWHERE t.Year=2020ORDERBY n.Neighborhood DESC, t.GeoId
TractId
GeoId
Neighborhood
0
26246
34005700103
Wissinoming - Tacony
1
26156
34005700104
Wissinoming - Tacony
2
26324
34005700200
Wissinoming - Tacony
3
26154
34005700303
Wissinoming - Tacony
4
25278
42101018400
Wissinoming - Tacony
...
...
...
...
996
26011
42101035702
Bustleton
997
25179
42101035900
Bustleton
998
25180
42101036000
Bustleton
999
25569
42101980200
Bustleton
1000
25176
42101980300
Bustleton
1001 rows × 3 columns
Aggregating Data (Group By)
Aggregating data to get counts or averages for example are usually done with the GROUP BY statement and keywords that go in the select statment.
For example, if we wanted to get a count of the number of census tracts in each state and year, we could run this:
SELECT StateFP, Year, COUNT(GeoId)FROM TractGROUPBY StateFP, Year
StateFP
Year
0
24
2010
19
1
42
2000
1069
2
34
2000
451
3
10
2010
164
4
34
2020
489
5
42
2010
1088
6
10
2000
127
7
34
2010
544
8
24
2000
16
9
24
2020
21
10
10
2020
187
11
42
2020
1157
When you are aggregating data, generally, every column in the SELECT clause must also be in the GROUP BY clause (except for the aggregated columns themselves).
This query would result in an error:
SELECT StateFP, CountyFP, Year, COUNT(GeoId)FROM TractGROUPBY StateFP, Year-- Column 'Tract.CountyFP' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
But something like this would not:
SELECT StateFP, Year, COUNT(GeoId), SUM(LowPop)FROM TractGROUPBY StateFP, Year
You might notice that the COUNT column doesn’t have a name in your results table. You can use the AS keyword to name it. You can use the alias in the ORDER BY clause as well
You can rename any column in the query as well, not just aggregate columns.
SELECT StateFP AS StateFIPS, Year, COUNT(GeoId) AS TractCountFROM TractGROUPBY StateFP, YearORDERBY TractCount DESC
StateFIPS
Year
TractCount
0
42
2020
1157
1
42
2010
1088
2
42
2000
1069
3
34
2010
544
4
34
2020
489
5
34
2000
451
6
10
2020
187
7
10
2010
164
8
10
2000
127
9
24
2020
21
10
24
2010
19
11
24
2000
16
There are several other aggregate functions that you could use to do data analysis:
Function
Description
AVG
Average of column/group
MAX
Max value of the column/group
MIN
Min value of the column/group
STDEV
Sample standard deviation of the values in the column/group
STDEVP
Population standard deviation of the values in the column/group
STRING_AGG
Concatenate strings in column/group, separate with deliminator
SUM
Sum values in column/group
VAR
Sample variance of values in column/group
VARP
Population variance of values in column/group
Exporting Data
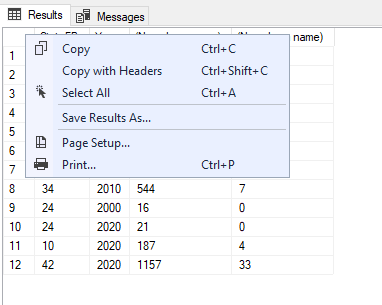
If you’ve already run the query you can right click on the table to copy the data or to save the results.
image.png
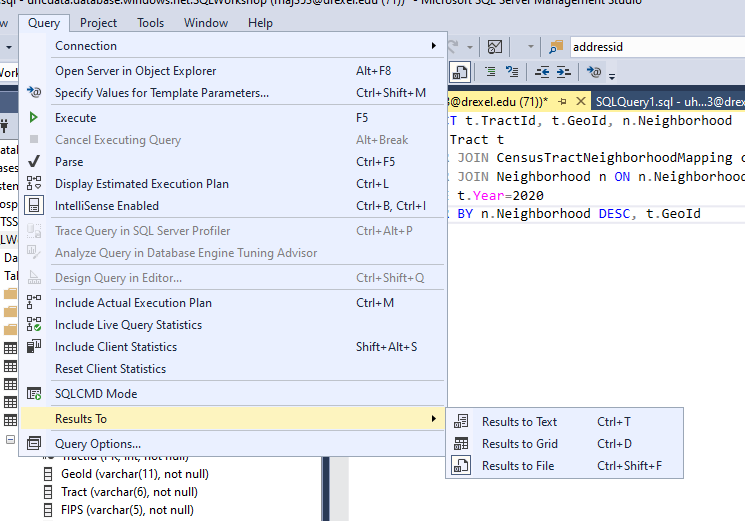
If you haven’t run the query, go to the “Query” menu, go to “Results To”, and select “Results to File.”
image-2.png
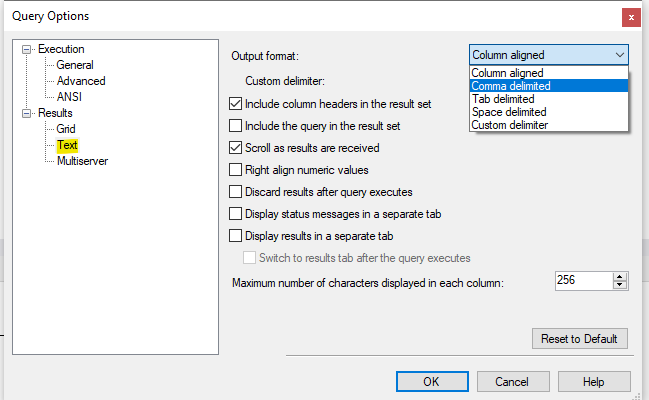
Press the execute button and it should open up a file save dialog box. It will try to export it as a .rpt file, but you probably don’t want that. So instead in the “Query” menu select “Query Options.” In the dialog box, you will want to click on “Text” under the “Results” section on the left side.
image-3.png
you can specify the delimiter using the “output format” dropdown menu. Comma delimited or tab delimited will let you save to a .csv or .txt file.
Importing Directly into Statistical Software
A lot of the software we use for data analysis can interact directly with SQL databases using the Open Database Connectivity (ODBC) protocol. You can pull directly from the database into an object in the piece of software of your choice. Here are a few examples.
Python
There are several options for connecting to a database in python. The below example uses pyodbc, but another common library is SQLAlchemy
import pyodbc# must have the correct ODBC driver installed, this should have been installed automatically when you installed SQL Server Management Studiocnxn = pyodbc.connect('{ODBC Driver 17 for SQL Server};Server=tcp:uhcdata.database.windows.net,1433;Database=SQLWorkshop;UID=maj353@drexel.edu;MultipleActiveResultSets=False;Authentication=ActiveDirectoryInteractive;')cn = cnxn.cursor()cn.execute("SELECT * FROM Tract")results = cn.fetchall()
R
library('RODBC')cnxn <-odbcDriverConnect('Driver={ODBC Driver 17 for SQL Server};Server=tcp:uhcdata.database.windows.net,1433;Database=SQLWorkshop;UID=maj353@drexel.edu;MultipleActiveResultSets=False;Authentication=ActiveDirectoryInteractive;')sqlQuery(cnxn, "SELECT * FROM Tract")