1 ETL
ETL orchestration is the process of managing the sequence and interaction of ETL tasks, which are:
- Extract: Data is collected from various sources.
- Transform: The data is modified, cleaned, or restructured to meet specific requirements.
- Load: The transformed data is then stored into a database or data warehouse.
1.1 Intro to Orchestration
Orchestration ensures that these tasks are performed efficiently, in the right order, and that data flows smoothly from one step to the next without issues. It handles scheduling, dependency resolution, and error management to ensure the entire process is completed as expected. This is important for a few reasons:
- FAIR
- Be able to find data products
- Be able to find the software
- Admin purposes but also enables effective collaborative software developement
- Centralize system for doing ETL
- Data quality is key
- unit testing at the pipeline level
- integration testing at the project-ETL level
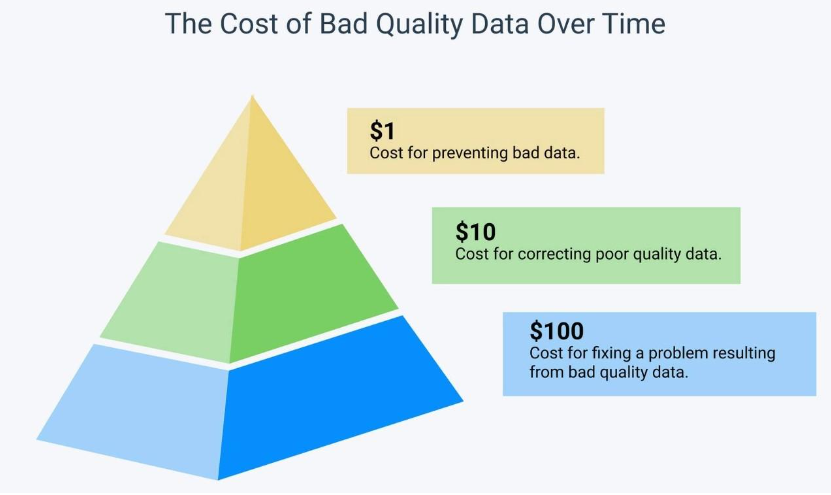
- Invest here to prevent bad data rather than paying for fixing bad data problems.
1.2 Orchestration Tools
There are many modern ETL orchestration tools that can be used to manage the ETL pipelines. We have evaluate a few of them such as MAGE AI which even has been used within the FAIR world - see this informal FIP from SEDIMARK. However many of these orchestration tools were not a good fit for our project at CCUH early phases due to a few key reasons:
- These orchestration tools require dockers to run locally.
- It is difficult to volume mount our primary storage (UHC Shared File System) onto Dockers instances
- While some orchestrators wrap useful tools such as DBT and R blocks. The wrapping of these tools within the orchestrators often had bugs or limited features of using these ETL tools in their native IDE’s (Rstudio or VS-code)
Due to these challenges, we could not find an orchestrator that fit our operating parameters at the time of CCUH setup in May 2024. So we wanted to set up a lightweight orchestrator using the tools we were familiar to implement many of the best practices found in existing orchestrators. We will design these key design principles and abstracts next.