9 Data Modeling
There are few key steps:
- Init. Source YAML
- Editing of metadata in source yaml
- Creation of base models
- harmoiznation into intermediate models
- then produce user facing models
9.1 Initalize Source YML (Single source of truth)
We do this via an ETL pipeline that sits within the DBT folder 2-dbt/.etl. This project essentially just reads int he semantic codebook and initializes a source yaml file for each table. The pseudo code looks like:
- read in semantic codebook
- operatoinalize as YAML
- If there source yaml does not exist within
models/sourcethen write it tomodels/source/{block_id}.yml - If the soruce file already exists do not overwrite as the DBT source YML is the single source of truth.
Note that the process produces a very minimal template including just name, type, description. Any other metadta either at the source/dataset or within data point level iis a little hard to atuomate so it is reocmend to enter these manualy. Which leads us to the shift in source of truth. At this point the Single source of truth for our datawarehouse items is compeltely in DBT. All upstream metadata is over rulled. This is because metadata is much easier to track and manage within DBT as there are guidelines, best practices and tooling to not only mange but also to make visible the metadata.
Todo: develop a GitHub issues/Projects workflow for trackign code-changes to data models over time. For example
9.2 Source YML Curation
Here we docuemnt common cases of enchrichment and edits.
9.2.1 Default initialized values
- DBT Source name (default value during initialization)
- DBT sources a one level folder for finding source files. (complex nested hierachies can be oeprationalize in base models. but sources are only one level.)
- Within a source there can be multiple tables
- so we need to conceptualize how we want to organize our sources. some options include:
- Project: SALURBAL vs USA
- Data source: PRISM, PA
- Pros:
- we can capture multiple tables per source. This might be useful when data updates happen.
- cons:
- this is a lto of work and we can capture
- most sources just one table
- Pros:
- don’t nest at ll and Keep everything under CCUH
- Pros:
- simple. lwo maintainance.
- Cons:
- findability doesn’t scale. the Sources table quickly becomes unfindable.
- we can’t capture multiple tables per source.
- Pros:
- initial decision. lets keep it simple. also the Source itnerface is already very limiting (only one layer of folders) so no matter what our stratedgy is the findability won’t scale. Its not worth the effort to try to make it findable. Lets just keep it simple and keep our data models organized or jsut rely on the search function.
- We will not change this and just keep the default value of
CCUH
9.2.2 Annotated fields
- Table Description:
- this is a descirption of teh source
- we can just copy content from Nthe GitHub PR and supplement wiht Notion or anything else
- reomcended to store this within a doc block operationlized in /models/docs/sources/index.md
- Tags
- This was not included int he initial ETL process; having the fleixbility to modify tags during the DBT process is crucial to organizing our models and soruces
- We will enchrich our source metadata during this process.
- here are a few types of tags to standardiez
dbt_{type}: dbt_source, dbt_base, dbt_int, dbt_marttable_{type}: table_death_records, table_area_levelscope_{type}: scope_usa, scope_usa_pageo_{type}: geo_tract10time_{type}: time_dailydomain_{type}: topic_mortalitytag_{topic}: tag_health, tag_environment
- Meta tag:
- This is custom section wehre we can input almost any metadata we want.
external_locationdata_sensitivitydata_point_level_metadata(e.g. tract10 population source to usa tract10 pops)
- tests
- for now we will just add some most common ones
- accepted
not_null
9.2.3 Init Base SQL model
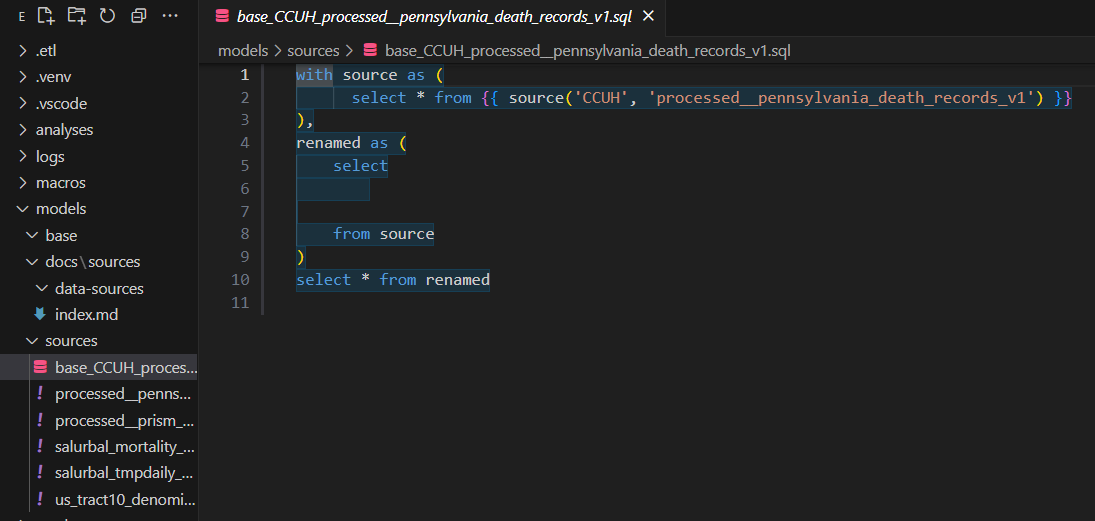
Note we just import all columns from source into base models. Its nice to have a that layer of validation that DBT generates column types rather than rely on source YAML we are not losing any data. We can always subset later.
THis is the next step and can be done automatically with DBT Power User. This extension will detect anytime you are in a source YML and gives a butto to Generate a base model. We can just click this button.
After we click this button we can see that DBT Power User has already initialized a base SQL model referencing the source YML. It has included some traditional base model boilerplate code which mainly jusst subests or renames the source data.
9.3 Design Intermediate models
Please refer to the introduction to data modeling for an explaination of common DBT layers. In summary source models are data as is from our upstream sources. For CCUH this means a diversity of scopes (SALURBAL, Philadelphia, USA Cities … etc) each with their own composite keys (salid vs GEOID, L1AD vs CBSA … etc) and variable naming (TMPDX vs tmean). For CCUH we will test the base layer as the place to start this initial harmonization to make these various datasets interoperable.
This process depends really on upstream need and is an active conversation between the data infrastructure and research teams. Here we document a simplified process that aims to harmonize two domains of data: death records and area level temperature data.
9.3.1 Death records
Lets start top down think upstream goal then work backwards.
9.3.1.1 Design intermediate table
int__ccuh_death_records is an intermediate table that will contained harmonized death records across the scope of the project. This table could have the following columns: