This section will give provide SOP for key technologies within our infrastructure
Parquet
HDFS local and server
HDFS Cloud
6.1 Parquet
Apache Parquet is a columnar storage format that is optimized for modern analytics. It is the foundation of modern analytics technologies such as Open Table Formats, OLAP data engines and high performance distributed computing such as Apache spark. Please refer to this chapter in R4DS for a more hands on introduction. Here are some of the benefits
Column data types are retained as metadata
Column data type is stored so you don’t have to worry about parsing integrers, strings, dates that get lsot in .csv files.
Efficient storage:
Data is stored in a highly efficient way so file sizes are many folds than other storage formats
Efficient analytics
Format optimized for big data queries
Effective for distributed computing
Open source
high iteroperability with modern data tools (Arrow, OLAP engines)
We can work with parquet in many languages (R, Python, JS, Rust, C++ … etc) with the Apache Arrow package.
6.1.1 1. Export tabular data as parquet
Here lets geernate some data and save it a parquet.
Notice how the parquet file is much smaller than the .csv file. This is because parquet is a columnar storage format and is optimized for efficient storage and access.
6.1.2 2. Import .parquet tabular data
Lets import the parquet and make sure all of our metadata is retained.
# A tibble: 6 × 5
id name value race_ethnicity date
<int> <chr> <dbl> <int> <date>
1 1 o -0.285 1 1999-01-12
2 2 s 0.381 2 1999-02-15
3 3 n 1.20 3 1999-03-23
4 4 c 1.08 1 1999-04-05
5 5 j 1.05 1 1999-10-10
6 6 r -1.62 1 1999-07-13
Notice how our original column types integer, character, double and date are all retained. This feature really helps data teams work effecitevly without having to worry about type casting getting lsot in translation.
6.1.3 3. Column type metadata
We have touched on one of key benefits of parquet which is the retention of metadata - such as column data type (e.g. int, string, date). But we can also store a lot of other metadata in our parquet files include spatial metadata (Coordinate systems) or even custom metadata such as column definition or column coding. Lets demonstrated this with the data we imported above. Lets demonstrate this with the data we created above.
First lets convert it into arrow table format.
arrow_table1 = data %>% arrow::arrow_table()arrow_table1
we can see the column types are strictly retained. But we could also change the metadata which in Arrow is called the table schema manually. Lets update two column types to adhere to best practices:
id
old: integer
new: string
Why: ID’s are commonly stored as a string instead of integer
name
old: string
new: utf8
Why: column is curently just a string but its good to specifically specific string UTF-8 encoding for complex names (e.g diacritical marks).
Below we define the new schema and update our table.
## Update datadata2 = data %>%mutate(id =as.character(id) )## Define new schemanew_table_schema = arrow::schema(id =string(),name =utf8(),value =double(),race_ethnicity = arrow::int32(),date = arrow::date32())## Update the table's schemaarrow_table2 =arrow_table( data2 ,schema =new_table_schema)arrow_table2
We can see the table’s metadata has been updated! We can save this as a parquet and now all downstream users will have this metadata automatically imported and have the correct column types. In addition to column type we can store almost any type of metatdata in parquet, please refer to the Parquet Metadata Documentation for details. Below we explore two common use cases for custom metadata: 1) embedding column definitions and 2) embedding categorical coding information.
6.1.4 4. Custom Metadata: Dataset and column
Here we follow R Arrow’s metadata documentation to demonstrate how to embed column definitions in a parquet file and how uses can access this built-in codebook. Essentially we when a data.frame is converted to an Arrow table which can be saved as parquet, any attributes() attached the columns of the original data.frame is also converted and saved.
Lets first initialize our example data.frame
## Initialize our demo data.framedata3 = data %>%mutate(id =as.character(id) )
6.1.4.1 4.1 Dataset level metadata
We can append dataset level metadata as custom key value pairs.
Lets check that this information is retained in our Arrow table.
arrow_table(data3)$metadata$r$attributes
$description
[1] "A simulated dataset for demonstration purposes."
$author
[1] "Harry Potter"
$author_orcid
[1] "https://orcid.org/0000-0002-9868-7773"
6.1.4.2 4.2 Column level metadata
It is also very useful to be able to write custom metadata at each column. In this example we will annotate our race_ethnicity column which is stored as integer for efficient processing but low acecssibility. Lets enrich this column with metadata to make it more accessible to users who get this file.
Indeed this metadata is retain in the parquet file.
6.2 Out-of-memory computations
One major benefit of modern analytics is the ability to work with datasets larger than a computer can load. Lets demonstrate how we can work with our data.parquet file without laoding into memory; importantly, this workflow scales and will alow analysts to easily work with datasets in the 10’s, 100s of GB or even Terrabyte sized datasets on normal labtops.
The first step is not to import the data but rather to connect with the data.
Notice how when we print the dataset object we don’t get a table but rather a abstraction called a FileSystemDataset and the metadata of the data inside this abstraction.
We can now run write our data wrangling logic and compute on this dataset without loading it into memory. For example here we write normal dplyr code - note that Arrow supports many data wrangling API’s such as python pandas or Rust Polars and many other languages.
# A tibble: 272 × 6
id name value race_ethnicity date id_name
<int> <chr> <dbl> <int> <date> <chr>
1 441 k 0.111 3 2000-01-01 441k
2 769 t 2.87 3 2000-01-01 769t
3 1259 e -1.43 3 2000-01-01 1259e
4 1280 z 1.02 2 2000-01-01 1280z
5 1901 u 0.161 2 2000-01-01 1901u
6 2168 c 0.467 3 2000-01-01 2168c
7 2690 q -0.854 1 2000-01-01 2690q
8 2721 o 1.13 1 2000-01-01 2721o
9 3224 z -0.0604 2 2000-01-01 3224z
10 3632 n 0.386 1 2000-01-01 3632n
# ℹ 262 more rows
6.3 File systems on Server
In addition to working efficiently and out of memory with a single file. We can partition how we store our files to accommodate the operating parameters of our hardware but also enable users to access the data not piece wise but as an single file system.
Add more details here and show some schematics
For example we have stored the CCUH PRISM zonal statistics as an HDFS. Here an analyst can access this entire resource both get the data thye want but also to run some basic data operations. Importantly, this allows us to utilize existing infrastructure such as the access controled drexel Servers.
So this data current is jsut for the state of PA and contains 161 million rows. with 5 geographic levels and 5 measures and 13 years of data. In .csv of other formats this would be many GB but we can access it quickly and only pull into memory the data we want.
For example an analyst wants to pull all tracts in Philadelphia for all measures and years.
## Get a list of Phialdelphia Census tractslibrary(tidycensus)tracts_philly =get_acs(geography ="tract",variables ="B01001_001", # Total population variable (used just to retrieve tracts)state ="PA",county ="Philadelphia",year =2020,geometry =FALSE# Set to FALSE since we only need GEOIDs) %>%pull(GEOID)## Query our datasetdf = dataset %>%filter( geo_level =="tract10", measure =='tmean', GEOID %in% tracts_philly) %>%collect()head(df)
6.4 File Systems on Cloud
So being able to work out of memory with parquet files and distributed file systems are really powerf. So far we have demosntrated how to do this on local and the UHC but for some applications we need to have this data exposed to non-drexel uesrs: for example external collaborators or a web application that is sitting on the cloud.
Fortunately, Arrow has built in functionality for doing this wiht no change in workflow. In this section we will follow the Arrow documentation on Using cloud storage (S3, GCS).
Lets first load the libraries we want
library(pacman)p_load(dplyr, ggplot2, arrow)
Natively, the R Apache Arrow package currently supports AWS S3 and Google Cloud Storage (GCS). We can confirm with:
arrow_with_s3()
[1] TRUE
arrow_with_gcs()
[1] TRUE
Okay. lets get started with S3. Voltron Labs is a company that developes dsitribtued data engines has a few HDFS parquet datasets on S3 avialable for public testing and benchmakring. Lets connect to their S3 Bucket … you can think of this as just a folder on the cloud. Bucket = Folder.
## Connect to bucket (aka folder)bucket <-s3_bucket("voltrondata-labs-datasets")bucket
So we have a few datasets in this bucket. Lets work with the nyc_taxi dataset as its a standard benchmarking dataset for big data. You can find more details on the NY.gov taxi site. Lets connect TO THE S3
There we go we are connected to this distributed file system! Lets try a query. This is a huge dataset with 17.7 billion rows and 24 columns. The total size in .csv format is more than 1TB.
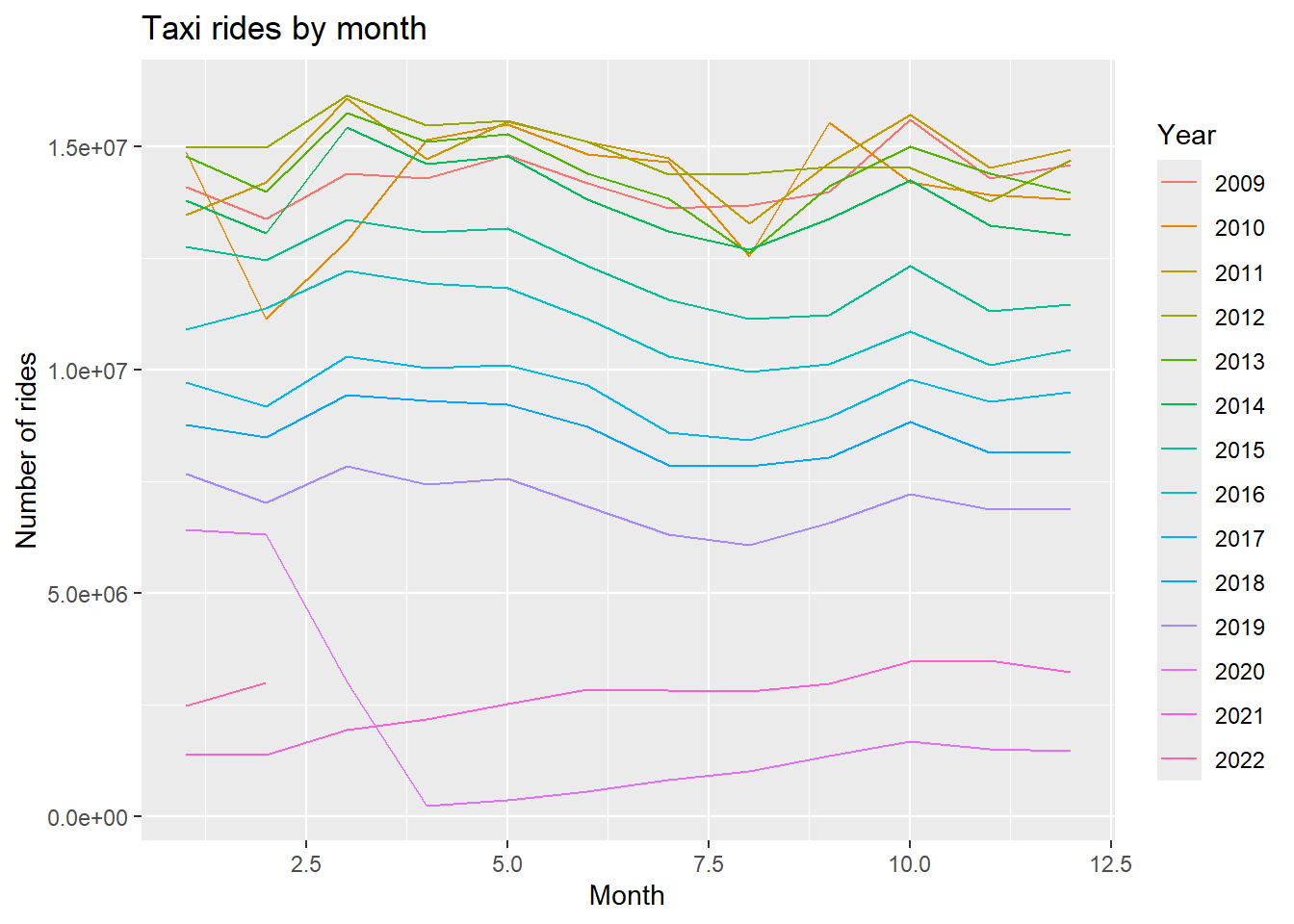
Notably, we can use dplyr to query the data. This dataset contains all taxi rides in NYC; lets a county of rides by year just to get a feel for the data.
So we have data from 2009 to 2022. Very interesting we can see that the number of rides has beend ecreaseing over time… makes sense given the rise of ride share companies such as Uber.
Lets do one more EDA, which months has highest counts of taxi rides.
## Count by year and monthdf2 = ds %>%count(year, month) %>%collect()## Plotdf2 %>%ggplot(aes(x = month, y = n, color =factor(year))) +geom_line() +labs(title ="Taxi rides by month",x ="Month",y ="Number of rides",color ="Year")
Interesting trends that summer is lwoer and peaks consistent in october.
6.5 Summary
Parquet is a columnar storage format that is optimized for modern analytics
Arrow is a high performance data processing library that can work with parquet files in many languages
Arrow can work with parquet files out of memory and on distributed file systems
Arrow can work with parquet files on cloud storage such as AWS S3 and GCS
This workflow can enable data teams to work with large datasets on normal labtops and share data with external collaborators efficently, securely and scalably without any additiona infrastructure costs.